This week
This week I spent my time working on the module that would extract features from paintings
Meeting 1
Since I was done with my curation I wanted some idea on how to proceed forward with my project and so I had mailed my mentors regarding the next steps for this project. This meeting was mostly oriented with what I had done and what are the results I could produce for the first evaluation. Since I had been involved in curation until last week I didn’t have any sort of output that could prove this usefulness of the data that I had collected and so I was constructed to come up with a simplistic module that would do something very simple. Like detect Mary in a painting or detect Jesus in a painting.
Next steps
After this I decided that I would use a FasterRCNN model pretrained on MSCOCO in order to extract features from paintings. Before that let’s understand how Faster-RCNN works.
Architecture of F-RCNN
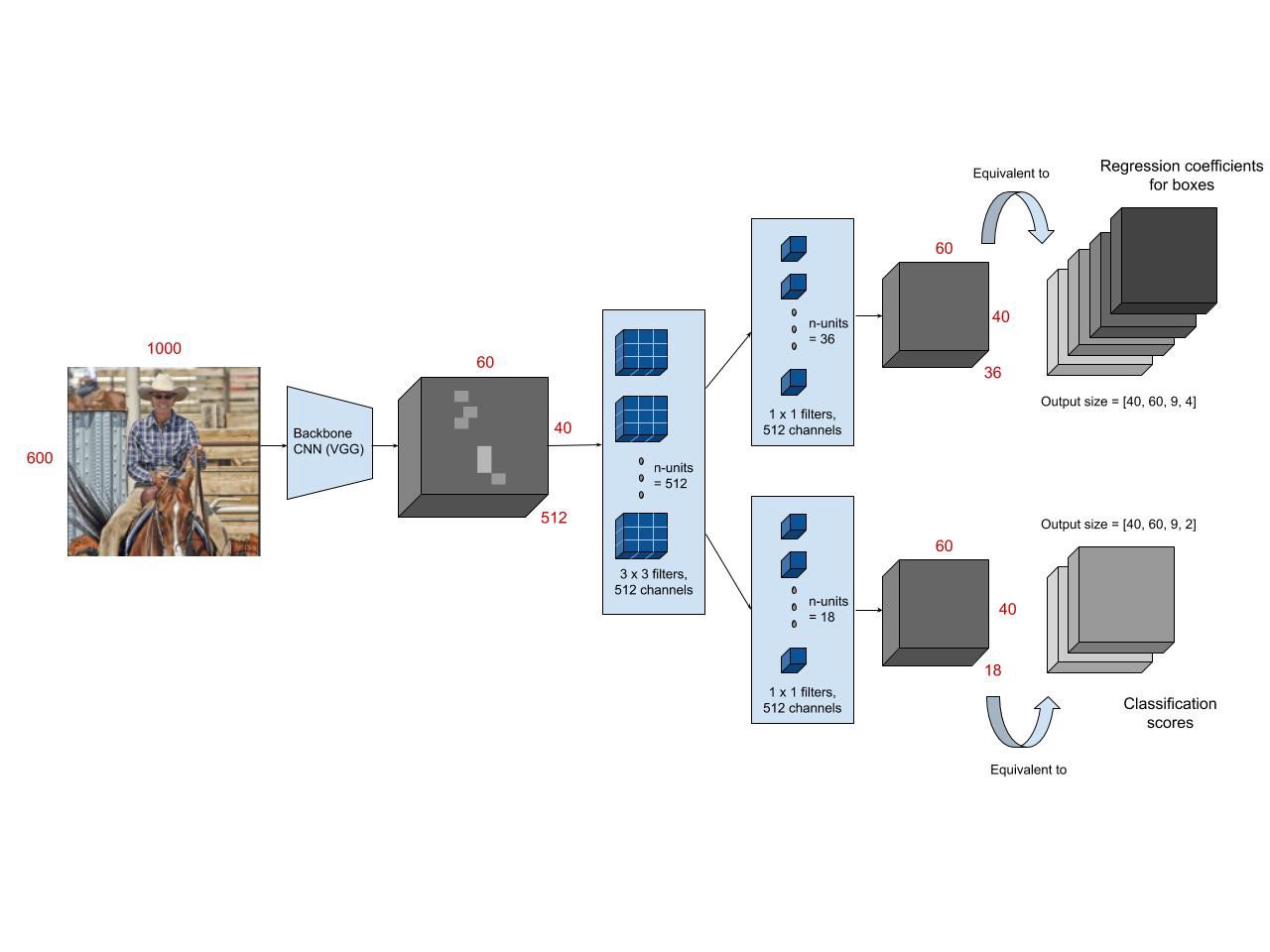
The F-RCNN consists of a CNN as a feature extractor. The CNN used here is normally trained on datasets like ImageNet or CIFAR-10 etc. Once the features are extracted we use an RPN(Region Proposal Network) to extract ROIs from the feature map representation. This is done using an ROI pooling layer which extracts the ROI from the images.
The ROI pooling layer generate N windows which are then passed into the classification and regression layer for loss calculation. Essentially this is where the gradients are calculated.
One of the advantages of F-RCNN is that the weight so the training occurs in 1-step.
Results with F-RCNN

So using the pretrained model on MSCOCO, I performed inference on the images from the dataset I had collected. From the results it was clear that the model is horribly failing at identifying different attributes that normally exist in a painting and so I decided to try out something different.
Trying out CNN as feature extractor
One of the problems with using MSCOCO as a dataset was that the MSCOCO dataset is more oriented towards modern objects so the only classes that would have been useful would be Person == Saint or animal (some paintings have this as an attribute for saints). Hence I thought that instead of doing object-detection I could directly use the features generate in the first step of object-detection.
What I did
So what I did is that I decided to train ResNet-50 on the ArtDL dataset consisting of 45k records of artworks pertaining to 19 saints. And in order to prove to my mentors this would be useful I tried using Grad-CAM++ on the images.

So from this what I inferred is that the pretrained CNN was extracting features around Mary’s crown her hand and the baby Jesus in her hand. The second image potrays Saint Jerome and we can see the features localizing around his pen his face which gave me confidence that we could indeed use this.
Meeting 2
So after doing this work I again presented my work to the mentors. We discussed the object-detection approach which essentially fails as expected so what I was suggested to do was to create bounding boxes around the images on my own and instead train a model on that. After discussion with the mentors, the second approach does feel good but since the captions are going to be complex there is no proof that this will actually work so for now I decided to annotate some images from the dataset I collected and report outputs on that.
Next week
Curating the object-detection dataset and completing enough work for phase-1 evaluation.