This week
- Deployed the pipeline to Case HPC
- Documented and commented the codebase
Current progress of the pipeline
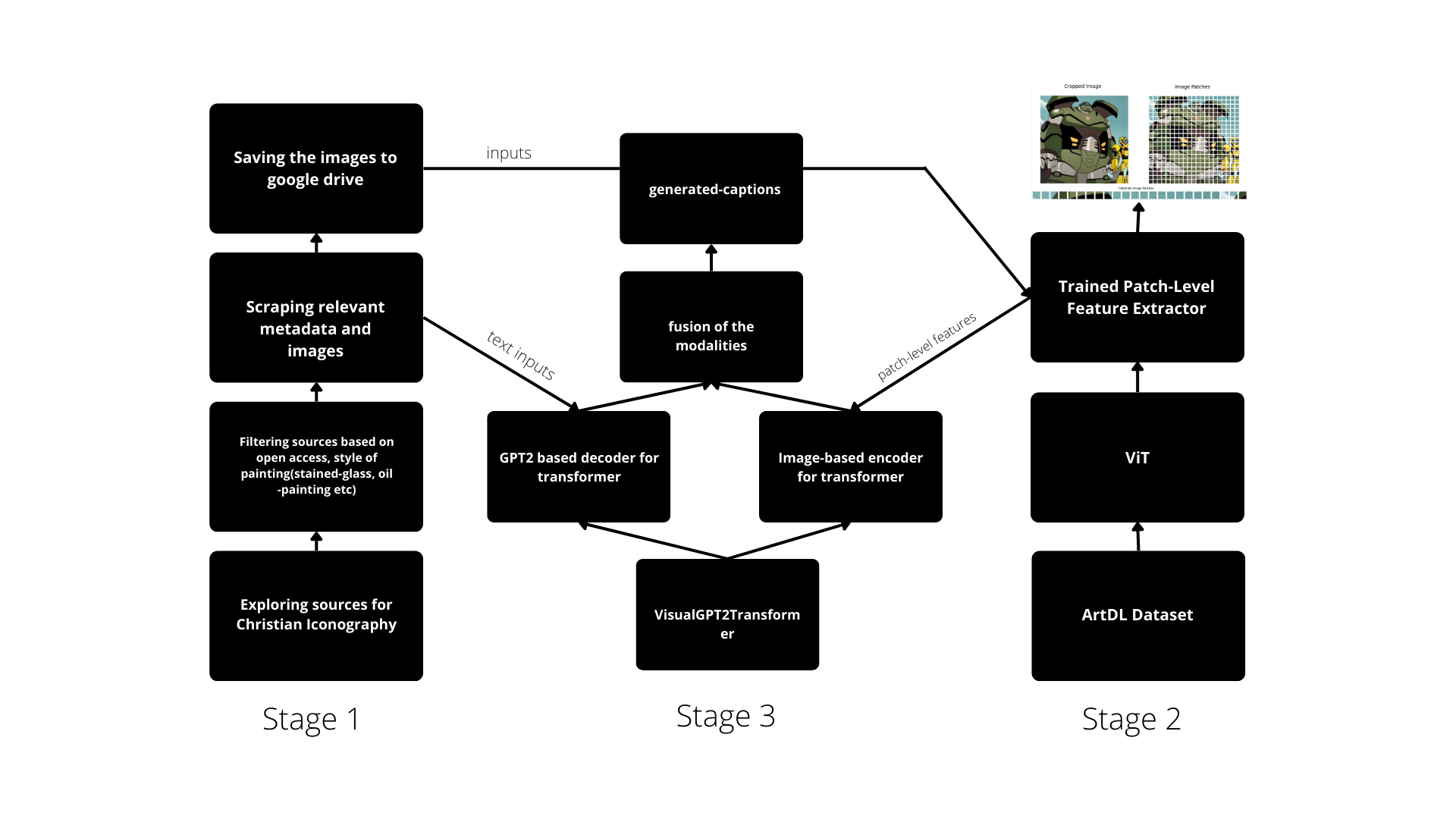
Stage 1: Curation
After working on collecting paintings related to Christian Iconography for 3-4 weeks. The final version of the dataset consists of approximately 9.6k data points.
Museums
- Web Gallery of Art - 5k images
- Art Institute of Chicago - 500-700
- Met Art - 500-700
- Corpus Viteraeum - 2k
- National Gallery of Art, Washington DC - 1k-2k
Artforms.
- Painting
- Stained glass
Metadata.
- Title
- Medium
- Artist
- Creation Time
- Description(Contextual meaning basically)
Note: The paintings itself are largely unfiltered.
Download the dataset and corresponding metadata here
You can also generate the dataset from scratch by using the curation module from my repository
Stage 2: Extracting features.
The Transformer model that I proposed requires a set of tokens/patches as input. In order to accomplish this I tried out two ways.
Using FRCNN
The first method that I tried out was using an object-detection model for extracting certain ROIs in the image. For this I again worked on generating a dataset consisting of around 500-600 images and further increased to 1200 images by applying data augmentation.
Following are the classes employed.
- Angel
- Arrow
- Baby
- Book
- Christ
- Cross
- Crown
- Cup
- Flower
- Fruit
- Horse
- Instrument
- Key
- Lamb
- Lion
- Mary
- Pen
- Saint
- Skull
- Staff
- Sword
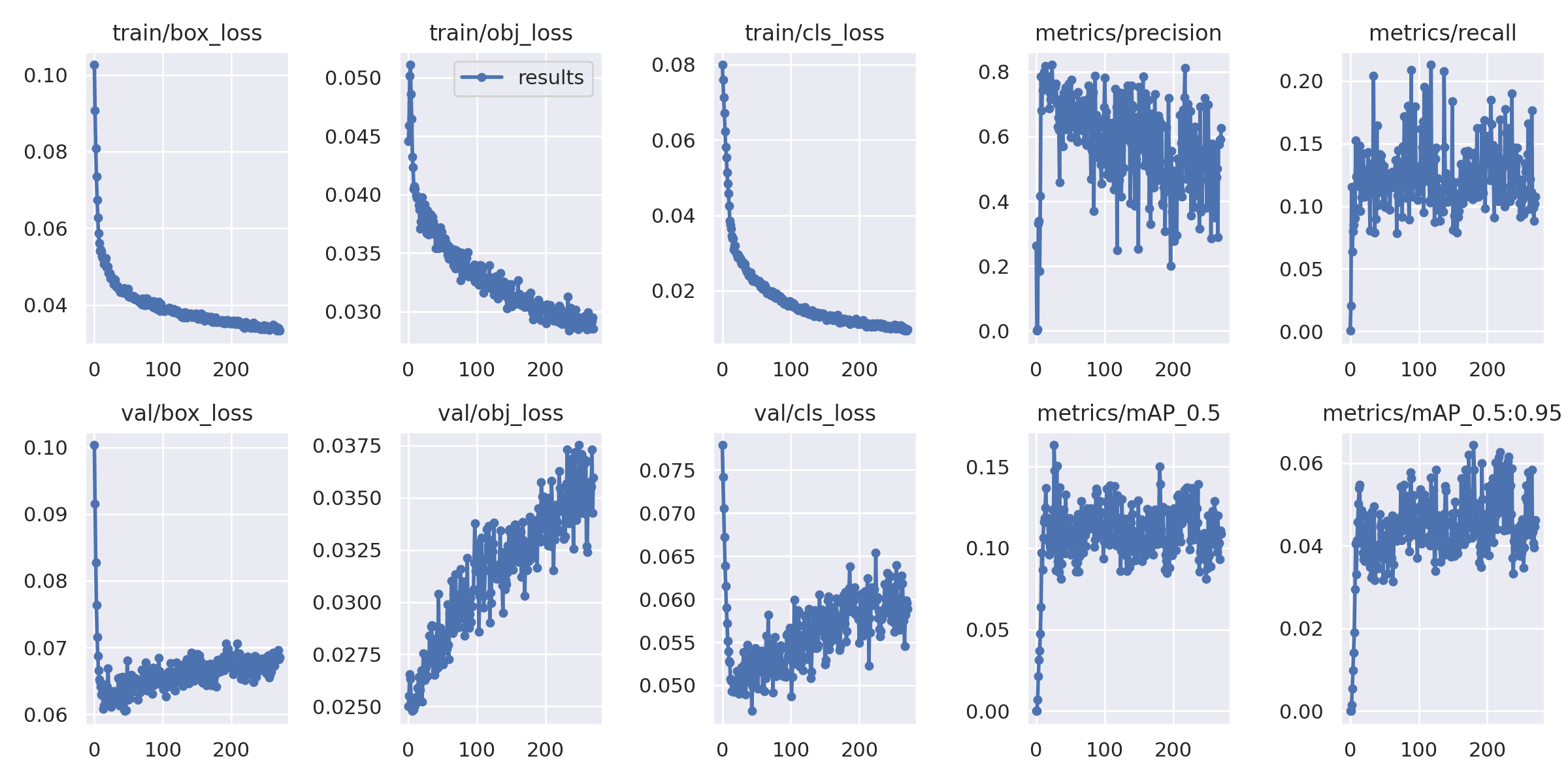
Performance
16.3% mAP
71.8% precision
14.3% recall
Training curves
Examples

Using ViT
One of the problems with using object-detection for feature extraction is that we need some datasets as a pre-requisite. While this is possible in case of real-life objects it is difficult when tackling paintings as there are not much datasets. Hence using ViT is a newer way to extract features. I have also mentioned why I have done this in my blog
Training ViT
While we can use pretrained ViT trained on datasets like ImageNet. The performance could improve if we trained it on a dataset in similar domain. Hence I decided to train the ViT on the ArtDL Dataset
ArtDL dataset is a recent dataset related to classification of saints in the paintings. It has over 45k data points spanning over 19 classes.
My approach towards using the ArtDL dataset was to reduce the problem a more simpler one. Given we are looking at a painting can we know whether the painting has mary a male saint or a female saint in it. By using this approach I reduced the problem to a 3-class multi-classification problem.
Performance
Epochs - 10
- Mary Accuracy - 75%
- Female Saint Accuracy - 95%
- Male Saint Accuracy - 95%
Note - In the dataset the instances of Male and Female Saints are less and hence there is a class imbalance that needs to be fixed. Due to those reasons we can’t really think of 95% accuracy in both cases as the actual result. I would have to do more work on these two classes to get robust results.
Stage 3 - Captioning
Final architecture
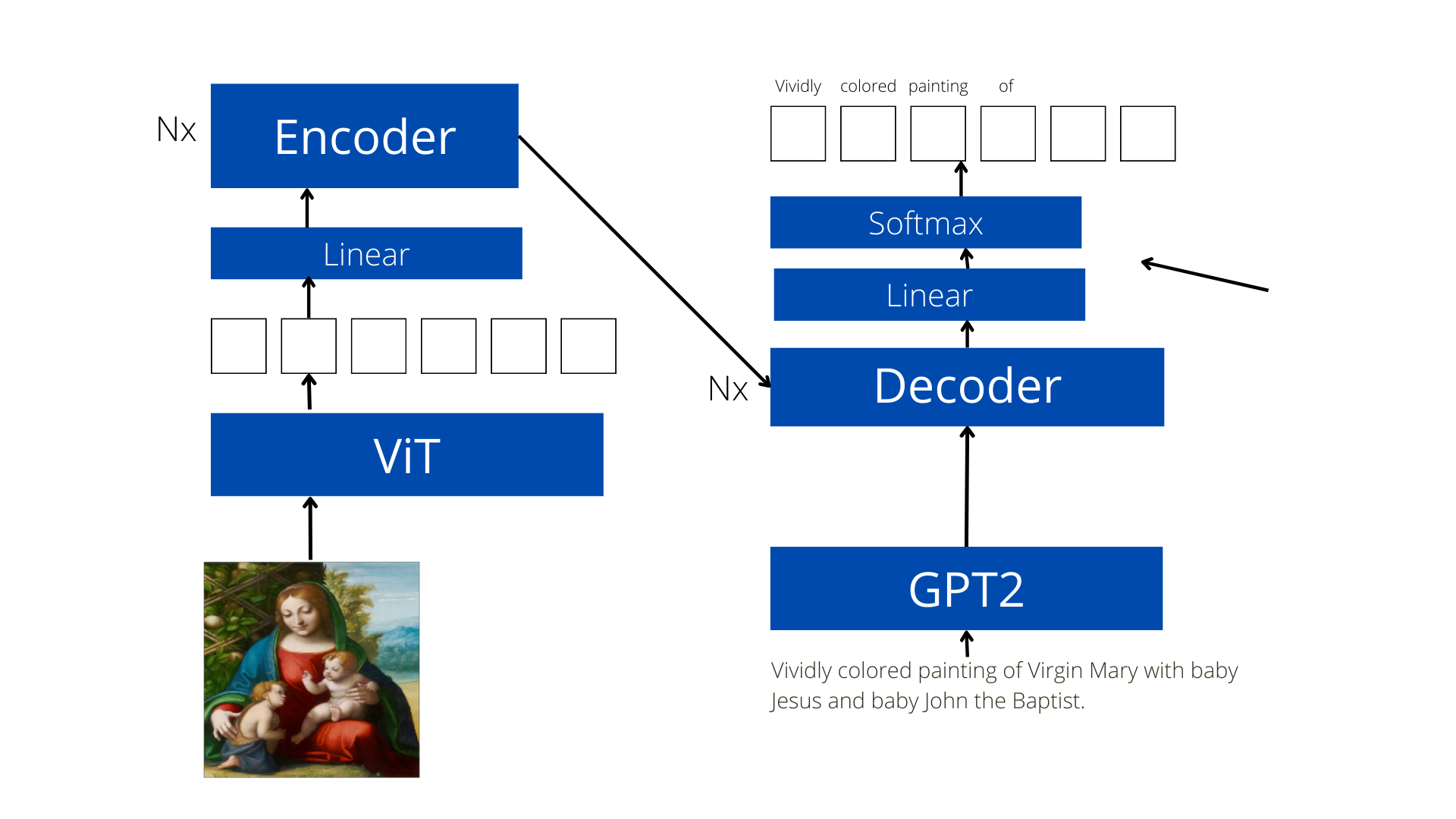 In the past few weeks I had tried out different language models and feature extraction models. For the finally architecture I have fixated on using ViT as my feature extractor and GPT2 as my language model/decoder. In this the feature extraction module is pretrained on the ArtDL dataset while the GPT2 is finetuned. We can also train GPT2 individually on a corpus related to this topic but I have got considerably good results even without this and hence for now I haven’t tried out this approach.
In the past few weeks I had tried out different language models and feature extraction models. For the finally architecture I have fixated on using ViT as my feature extractor and GPT2 as my language model/decoder. In this the feature extraction module is pretrained on the ArtDL dataset while the GPT2 is finetuned. We can also train GPT2 individually on a corpus related to this topic but I have got considerably good results even without this and hence for now I haven’t tried out this approach.
Performance of the model
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | CIDER |
|---|---|---|---|---|---|---|
| 0.314 | 0.172 | 0.101 | 0.052 | 0.141 | 0.312 | 0.068 |
Since we don’t have other datasets or models on this. This can be thought of as the current-benchmark for this architecture. In future this will be updated accordingly as I try out more approaches towards captioning
Example
Here is an example that I had shown during the demo of my pipeline.
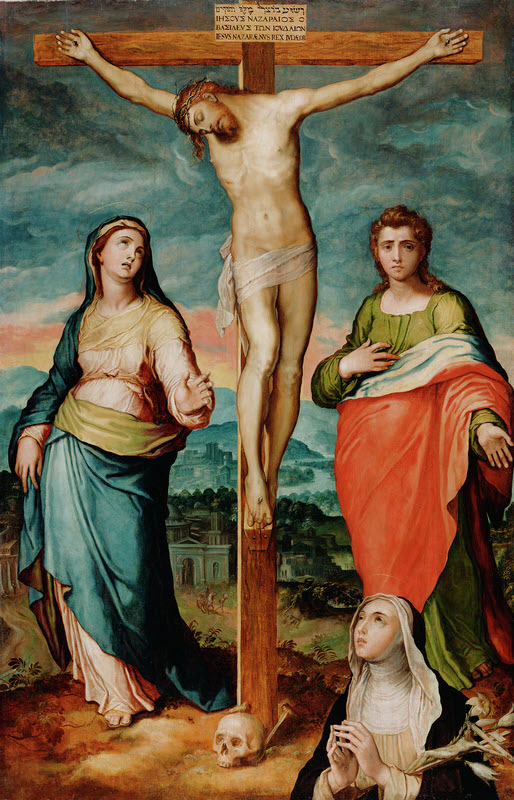
Using prompts
In order to generate captions the model I have built uses prompts. A prompt is a simple thing like “What is in this painting” , “Caption this painting”. Since GPT2 is very useful for text generation I have modified the dataset in a way that each title/caption has some random prompt associated with and so during inference we pass in the image and a random prompt to generate the caption.
So in context with the image I have used, these are the prompts and the results.
Describe the painting.
Answer - Christ on the Cross
What symbols do you notice in the artwork?
Answer - Virgin Mary
Describe the icons in the painting
Answer - Saint John
And this is the actual title that was not passed during inference Christ on the Cross with the Virgin, Saint John the Evangelist, and Saint Catherine of Siena in Adoration
While the model is not absolutely perfect it is still able to generate some meaningful inference from the painting by using an image + prompt
And here are the defined prompts I used during training
Describe the painting.
What’s going on in this artwork?
What title would you give this artwork?
What symbols do you notice in the artwork?
What is the subject matter
Describe the agents in painting
Describe the icons in painting
Best title for this painting
Caption this painting
Describe the artwork
What is this painting about
" "
Future plans
Looking back I feel like I have accomplished a lot of things in a domain that has not been explored much but since this is a new thing we can always do more.
-
The first thing I want to continue work on is to generate more detailed descriptions of the paintings. So it should not just caption the agents in the paintings but should also describe properly what the agents might be doing and some story that we don’t know of. This is a relatively difficult task to take I am still working on. The progress can be viewed in this notebook.
-
Next step is to leverage both images and text in the Emile Male Pipeline. While my captioning model uses both of these by fusing the modalities during training. We don’t use these captions during inference and the only text we rely on are the prompts. In order to improve this I have tried to work on using the titles for generating captions that tell us about the finer details. This is what the first point also stresses upon.
-
Another idea I am thinking of is to build a search tool for enthusiasts in Christian Iconography. The idea is that the user will send in a title and the model could retrieve images similar to it. I feel that this would be a really useful thing for people just getting started with Iconography.
The code
The results, implementation of the methods discussed can be found here
Deploying the pipeline
The pipeline is built in a modular way but they all combine together to form the Emile Male pipeline which is ready to be used on the Case HPC. Know more on how to do this in my README