This week
- Implemented the transformer model for captioning task
- Presented the demo of the pipeline to the mentors
Changing the dataset(torch.Dataset instance i.e)
Earlier the dataset instance of PyTorch that I was using was simple. Whenever I referred an index it would return the image and numericalized version of the caption. But I wanted to use GPT2 for what it is good for. Hint: Text generation. So I changed the captions by providing a prompt as a token. A prompt would be really simple like “What is happening in the painting” or “Who is in the painting” and so the idea is that by passing these prompts the model will look at the image and generate a response describing the painting. I felt this is similar to how we function and hence I added it.
These are some of the prompts I used.
Describe the painting.
What’s going on in this artwork?
What title would you give this artwork?
What symbols do you notice in the artwork?
What is the subject matter
Describe the agents in painting
Describe the icons in painting
Best title for this painting
Caption this painting
Describe the artwork
What is this painting about
" "
Notice I have used an empty prompt as well. That is because the model should be able to function just about fine even if we don’t pass a prompt
Implementing the Transformer
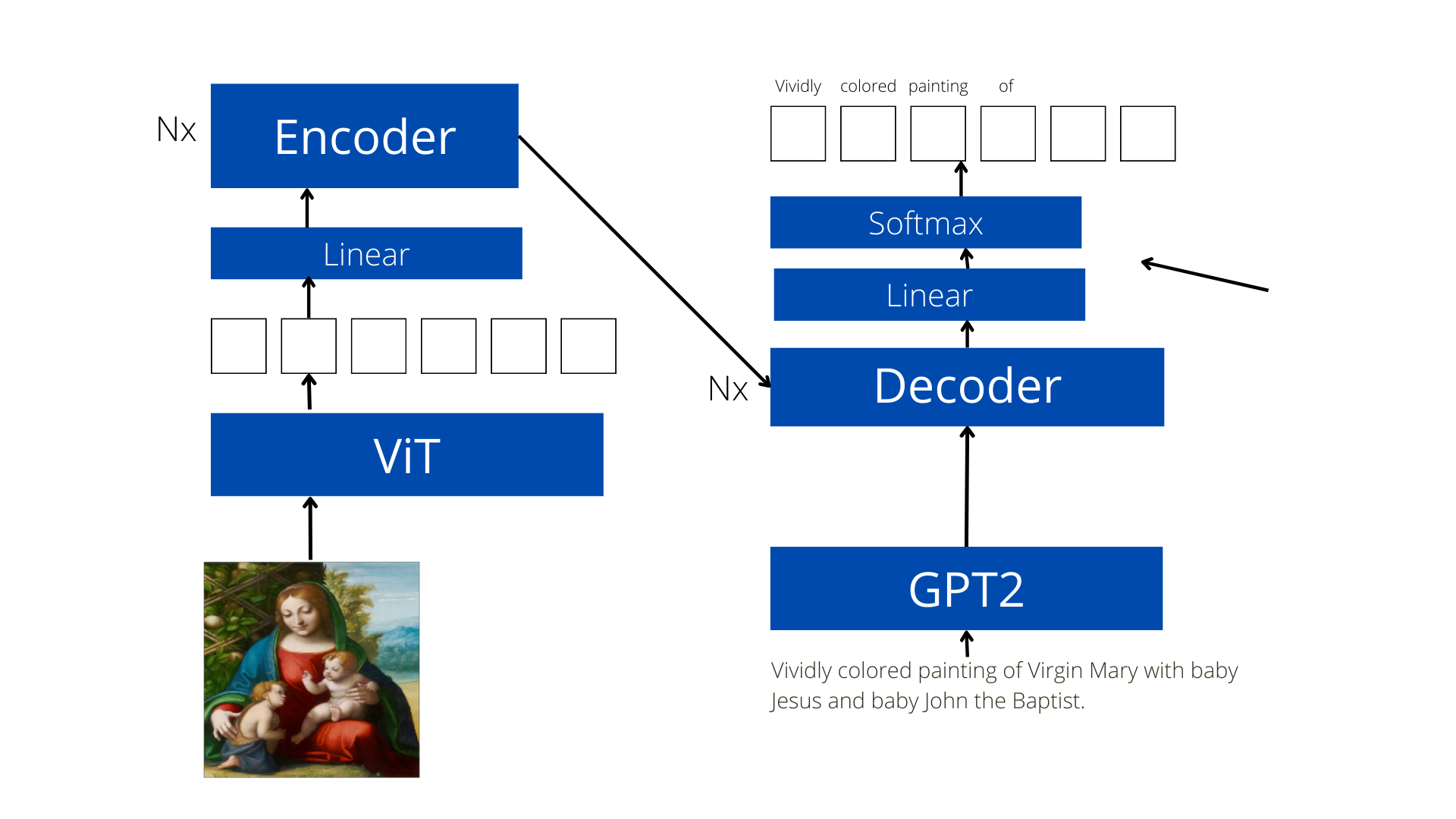 Over the past few blogs we have seen this model architecture a lot. This week was the one when I finally implemented. As discussed in last week’s blog I have changed the feature extractor from FRCNN to ViT and the decoder inputs from a Word2Vec+LSTM model to GPT2 based one. I have also added stacks of encoder and decoder blocks to these inputs and finally fused the modality by using the outputs from the encoder block and used them as inputs in decoder block as well. This way we have image-to-image, text-to-text and image-to-text interactions thus making the model multimodal.
Over the past few blogs we have seen this model architecture a lot. This week was the one when I finally implemented. As discussed in last week’s blog I have changed the feature extractor from FRCNN to ViT and the decoder inputs from a Word2Vec+LSTM model to GPT2 based one. I have also added stacks of encoder and decoder blocks to these inputs and finally fused the modality by using the outputs from the encoder block and used them as inputs in decoder block as well. This way we have image-to-image, text-to-text and image-to-text interactions thus making the model multimodal.
Meeting+Demo
In this week’s meeting I was supposed to show the demo of the pipeline. After explaining the working of my model I showcased the demo on a test image shared by one of my mentors Marcelo. The painting was of Jesus hanging on a cross and surrounded by Mary and another Saint. The model I had built was able to successfully describe some of the agents in the painting.
Next my mentors asked what do I propose to do in the remaining days of this programs. I proposed that with certain improvements in the captions I had collected, we could improve the performance even more. Finally I also said that I would make this pipeline work on Case HPC which would subsequently mean the end of this project (at least for the Google Summer of Code)
Next week
-
So the plan for next week is to first deploy the pipeline to Case HPC and then work on improving caption quality. While there are still some things I would love to work on. I can only intend to work on them once the initial deliverables are completed.
-
While the model is built I have to properly evaluate it by using different captioning metrics like BLEU, METEOR, CIDER etc in order to prove the usefulness of the model. Hence I will work on an inference/testing module for the same.