This week
- Used a transformer based model to work on the captioning task
A Transformer that uses images + text
During the last week’s meeting I had concluded that using models like Word2Vec might not always work as they have a fixed representation of each word but words can differ contextually so this week I decided to use some better language models like GPT2 and BERT.
VisionEncoderDecoder
For incorporating transformer I used huggingface’s VisionEncoderDecoder implementation which helps us in initializing any vision-transformer(ViT, BEiT etc) based model as the encoder and a language model(GPT2, BERT, RoBERTa etc) as the decoder.
Using a ViT and not an object-detector
While using ViT as a feature-extractor in encoder is good but in the past few weeks I had also worked on an object-detection module to do the same task. So why change now?
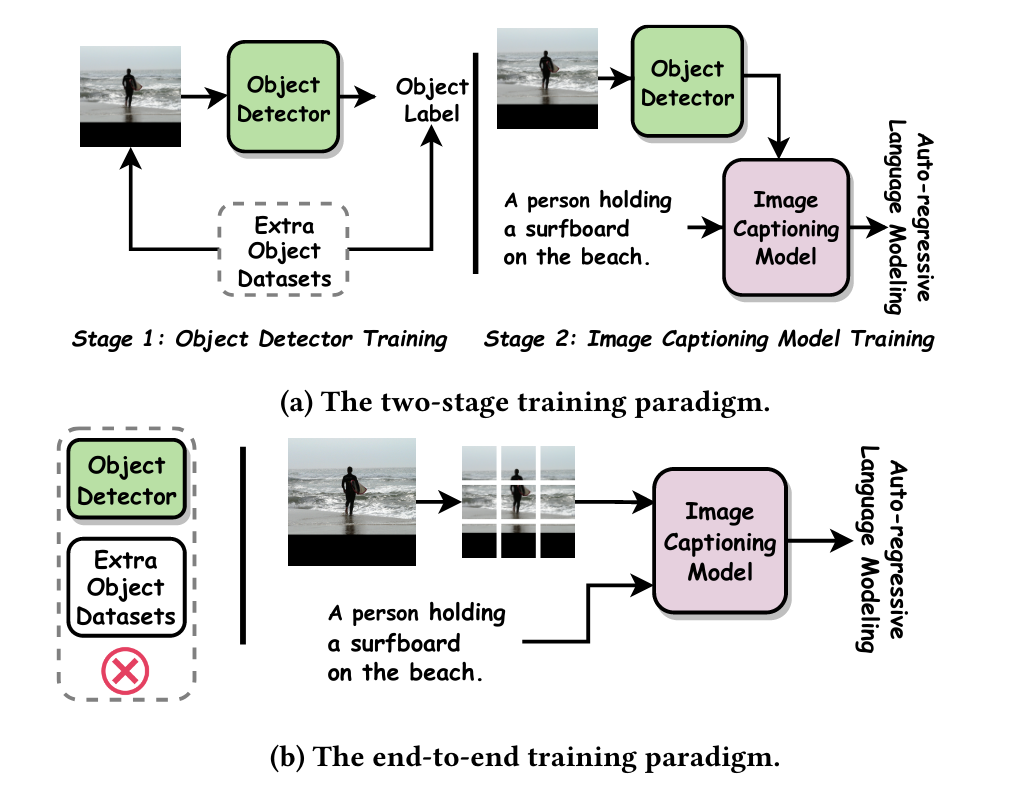
The answer lies in the image. Normally image-captioning models that use object-detection require another dataset that has if not all then at least some objects that will be used in the dataset for captioning. Now this method is fine if we are working with captioning of a real-life object as we have well-harvested datasets like MS-COCO or Visual Genome. But with respect to art there doesn’t exist much. In fact w.r.t to Christian Iconography there is only one dataset that tackles object-detection and that is also not for all the vast amount of saints we know of. In such a case using ViT can be really beneficial. By using a Vision Transformer we can convert image into set of tokens/patches. By doing this we are basically viewing each and every corner of our image unlike an object-detection model that normally uses a CNN backbone. Next similar to an object-detection model we can assign importance to these patches by using the concept of attention. This way we discard any useless information in the image and since we can finetune this model we can improve the performance of it while training of course. Hence, due to the mentioned points I decided to try out ViT as a feature extractor
Image taken from this paper
Results
So by following the methodology I used ViT as my encoder followed by using GPT2/BERT as my decoder. I padded the texts to max_length batch wise and started training. This is where things got interesting. Somehow the loss kept on reducing to really low values in the range of 0.000455. This meant that the model was fantastic at doing what it was supposed to do but turns out it was not the case. During inference all the model was doing was predicting i.e end of sentence tokens. I tried doing lot of things to tackle this but somehow it was not working.
Next week
This brings me to the plan of action for next week. Somehow the vision_encoder_decoder of huggingface was not working out for me and since there was not much documentation for the same, I decided to implement a transformer from scratch and include ViT and GPT2 implementations from huggingface as add-ons to my own transformer. I felt this would be better as I would be able to control the things that I was not able to see in huggingface implementation and also understand the working of my model in a better way.