This week
- Worked on using the captions I had collected during the curation stage
- I also build up a CNN+LSTM model to see if we could achieve good captioning results without use of Transformers
Approach towards using the text.
A image captioning model makes use of both text and an image but interpreting text can be difficult. Normally to solve this we use word embeddings which give us an idea about the similarity between two or more words.
In this week I focussed on training a word embedding model that could learn to associate the various agents in our painting. To give an idea if we have Mary then we should words like Virgin or Christ appear more nearer to her as Christ is her son and Virgin is a title associated with her.
Here is the workflow for the same
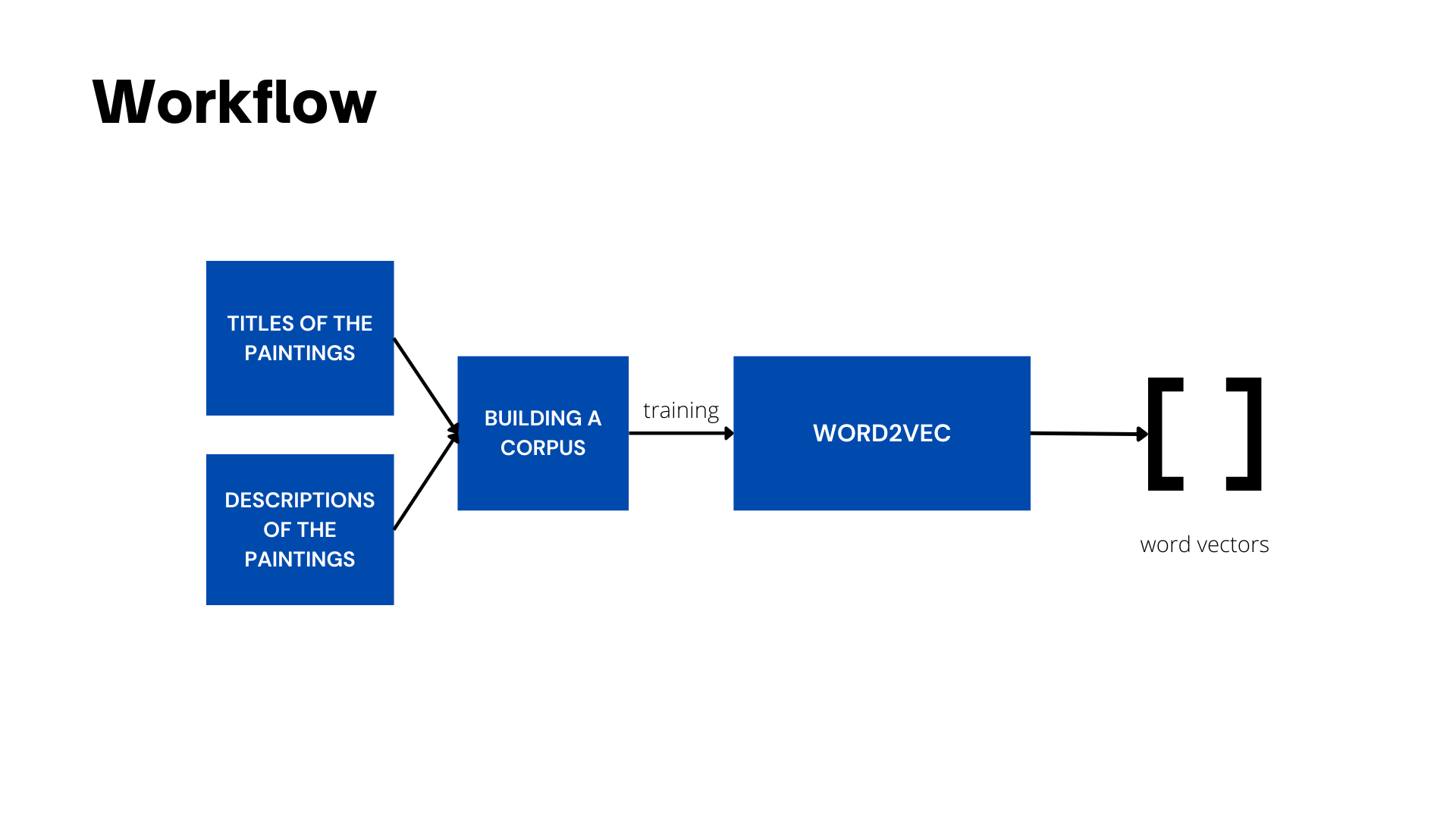
The idea is to train a Word2Vec model that will learn to interpret the text and give us some understandable representation of what we know about Christian Iconography. So for instance when I pass ‘John The Baptist’ to my word2vec model it should predict some words like Mary, Christ being the closest words according to Christian Iconography.
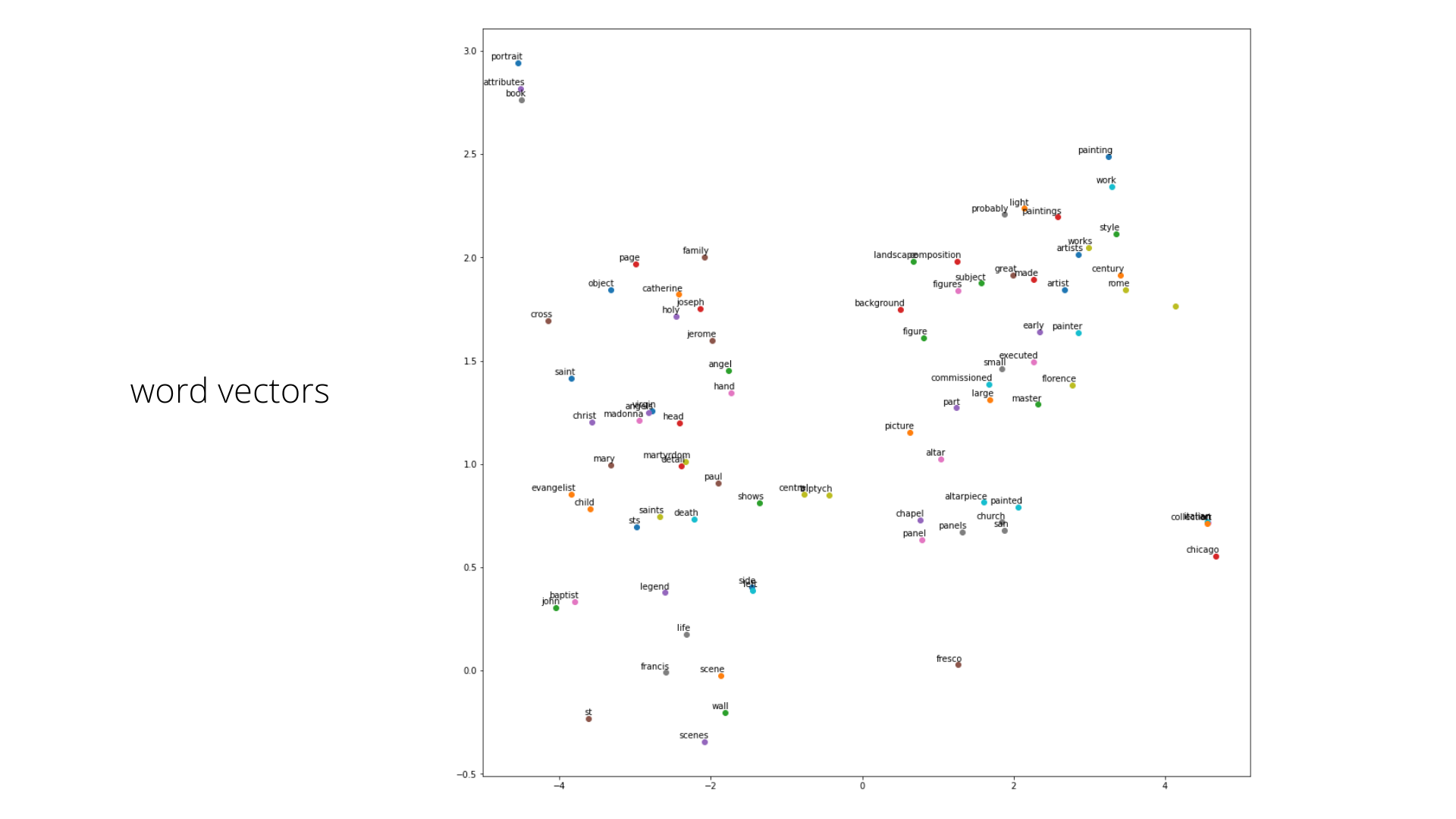
Here are some preliminary results of the training. I have used gensim’s word2vec implementation for training on the corpus
1. Virgin Mary

2. Saint Sebastian

3. Representation of the words as vectors
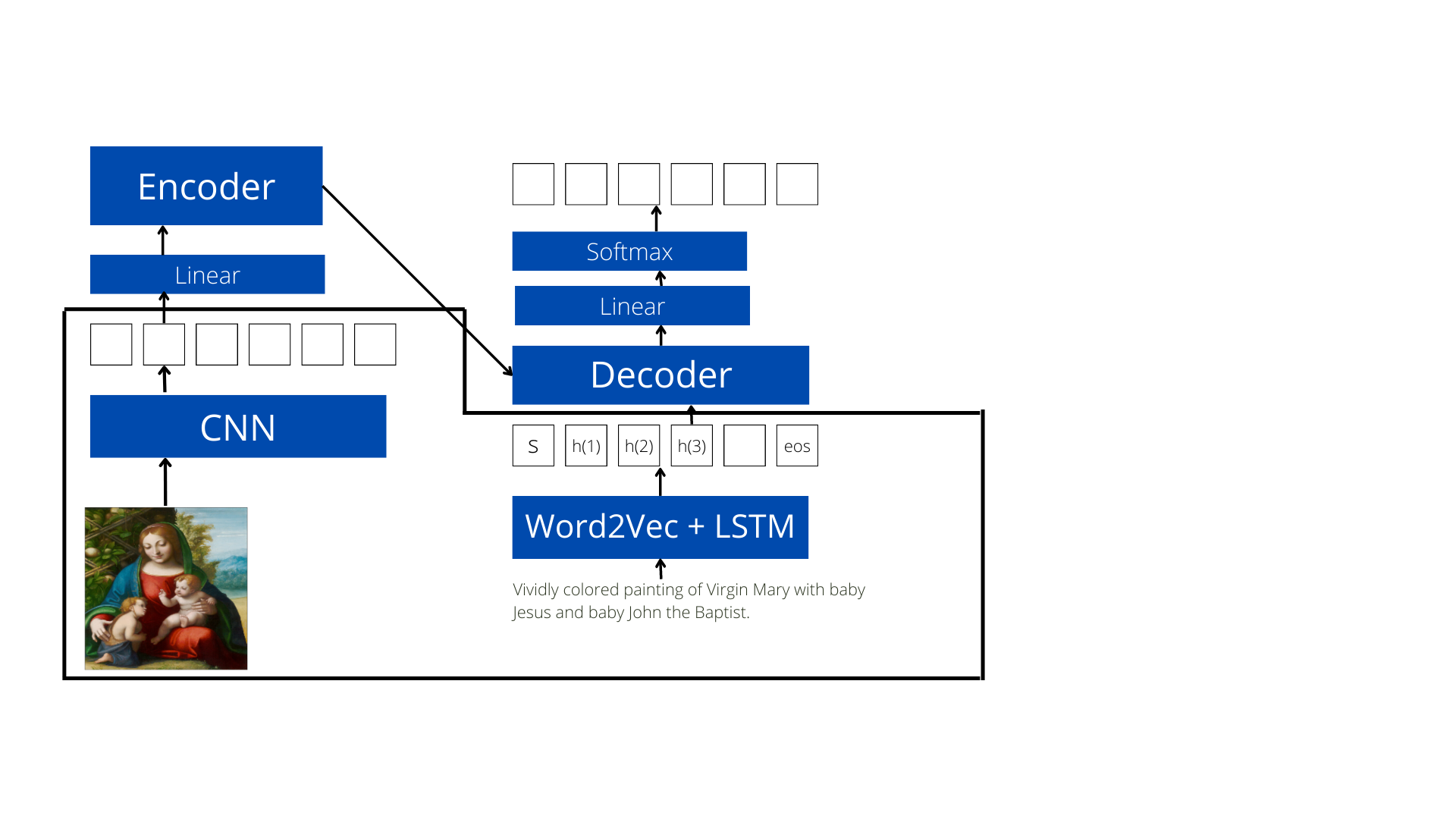
Building a captioning model
Since past few years, captioning models generally use an encoder-decoder strategy where the encoder is a CNN and the decoder is an LSTM. Since I had implemented these parts I felt it would be good to test out this strategy and see if I could build something without using a Transformer.
The workflow of this model generated from the overall workflow of my captioning module
I trained this model for 10 epochs and the loss reduced steadily till 0.4. Following are some of the captions generated using this strategy.
Example1

Example2

If we observe, the captions generated are far from perfect.
Another interesting thing happening with the model I trained.
For a lot of the images the caption is as following the holy family with st john the baptist. I am not sure why this was as the loss was constantly decreasing. I think it might have something to do with word2vec as it misses out on contextual understanding of words and tries to represent each word with a fixed vector.
To give an example if word bank has a certain representation in word2vec then two statements river bank and bank robbery might have almost same representation
Meeting
Based on last week’s discussion I was supposed to show how I was planning to use text in my model. So I showcased the results of this blog. I got some suggestions regarding using language models that are trained on a large corpus (gpt2 for eg). I was also suggested to use sections from Emile Male’s book as corpus to improve the performance of my model. Apart from that I was instructed to showcase a demo of the captioning process for next week
Next week
- Exploring some language models like GPT2, BeRT
- Also finishing the captioning module for demo