This week
This week I completed the module that extracts various attributes from the paintings. Apart from that I will be showcasing in this blog whatever I have done in phase-1
The Modified Pipeline
1. Data Curation.
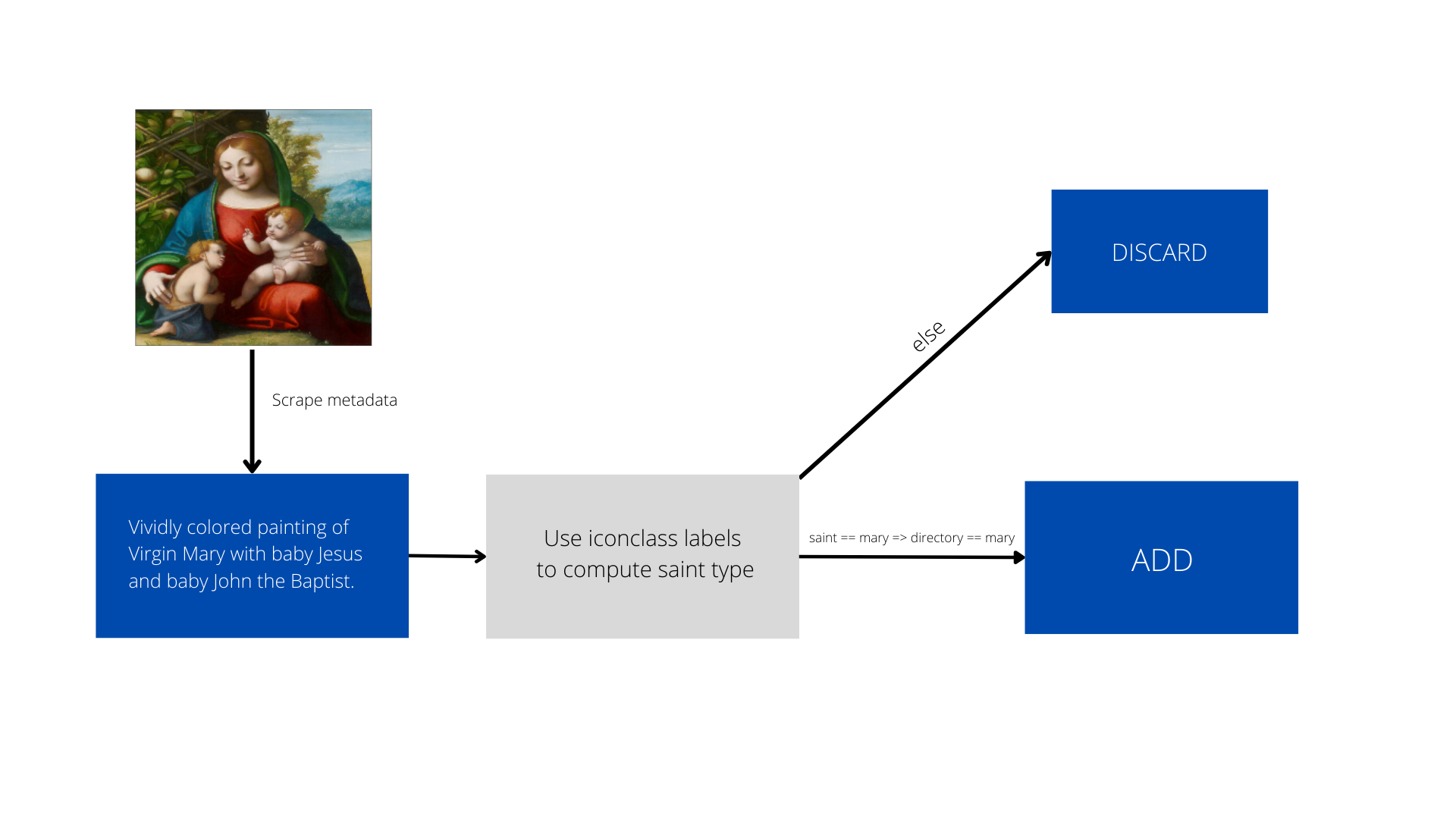
2. Image Captioning Model
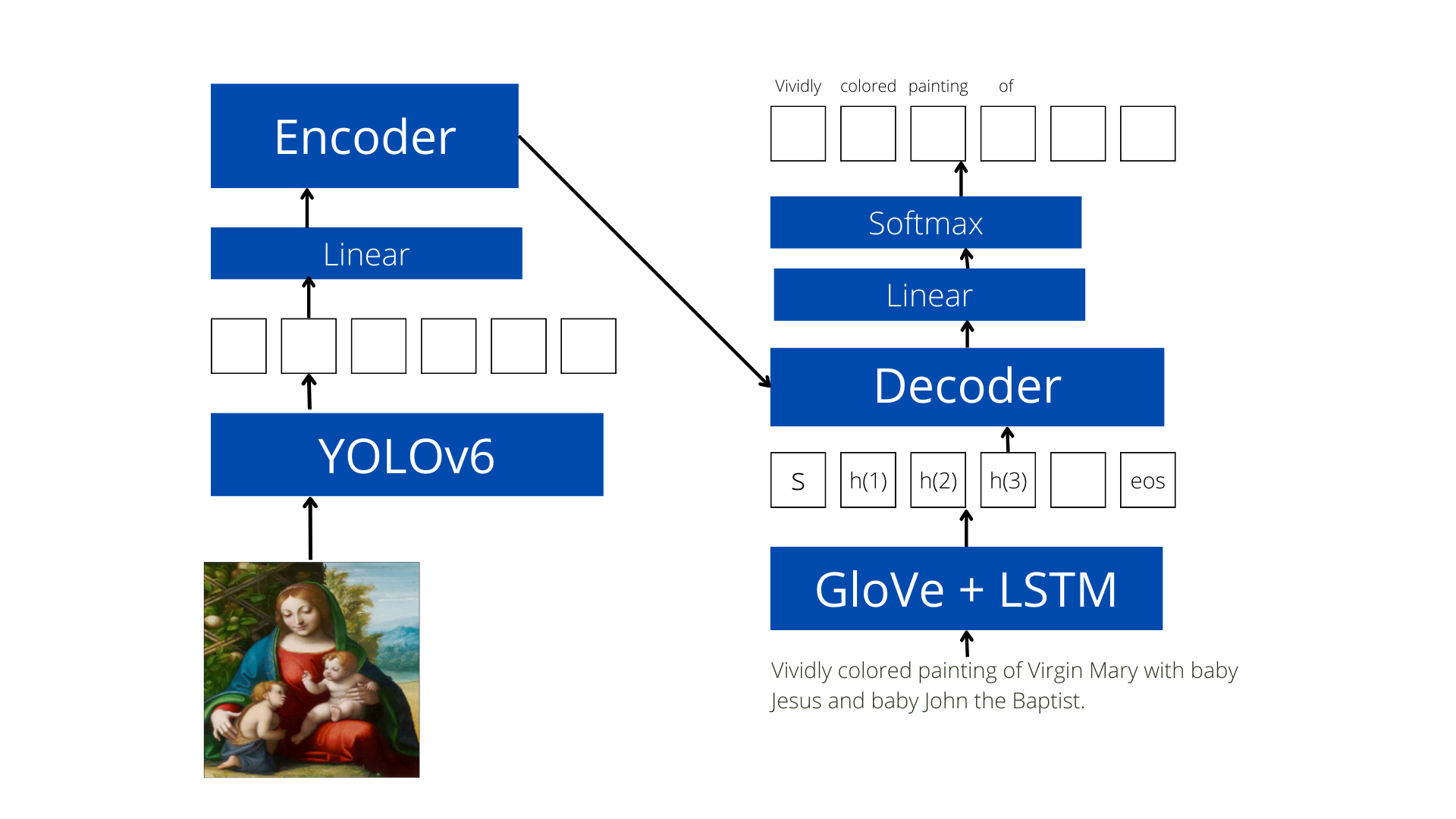
Changes
-
I have made very minute changes to the pipeline. One of my goals was to create a module for adding more data points but I have kept that on hold. Instead we just compute the saint label and directly add the image to a database. If I have more time I would definitely want to build something more concrete out of this.
-
Second thing I changed was the Object-Detection module which in itself was part of the image-captioning module. Instead of using Faster-RCNN I have used YOLOv6 which gives me better performance and will be showcased in the later sections of this blog.
The process for curation
Since the problem of using Christian Iconography in AI is relatively new. The fact is that there are no datasets for the same and hence my first task was to curate one. After the initial meeting with my mentors I understood that what we need to focus on is something simple. For eg why not just stick to tagging renaissance paintings and then later expand to other categories or just identify what Mother Mary might be doing in a painting.
After this discussion I decided to stick to paintings of saints and Mary included. The task would be simple. Given a painting that contains an image of a saint what is he/she doing?
Based on this I started I looking into various museums that could give me open access to data. After exploring this subject for around 2 weeks I logged down my sources here and decided that it was time to start with the curation.
The process of curation is a tiring one is what I have found but nonetheless it was interesting and fun. I learned a lot of things related to iconography and information retrieval. Taking Mark’s advice I utilized images found in museums belonging to the renaissance era with different artforms like fresco, oil paint etc.
Analysis of the metadata.
After working on this task for 4 weeks I curated around 10,000 images containing iconographic content in them.
Sources.
I have curated images from 5 sources.
- Web Gallery of Art - 5k images
- Art Institute of Chicago - 500-700
- Met Art - 500-700
- Corpus Viteraeum - 2k
- National Gallery of Art, Washington DC - 4-5k(WIP)
Artforms.
- Painting
- Stained glass
Metadata.
- Title
- Medium
- Artist
- Creation Time
- Description(Contextual meaning basically)
Analyzing the timeframe of the paintings.
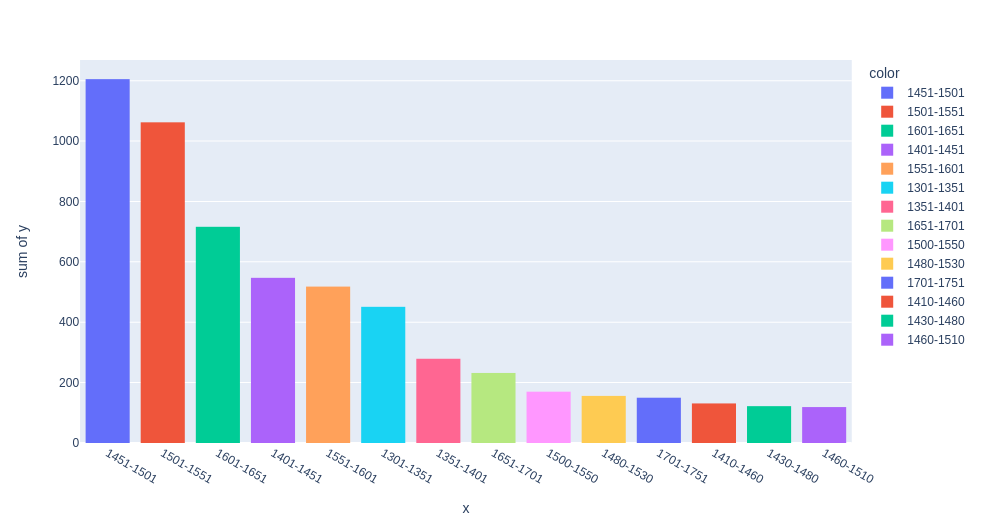 Out of the 10k paintings collected what we observe is that most of these paintings come from the renaissance era.
Out of the 10k paintings collected what we observe is that most of these paintings come from the renaissance era.
Analyzing the medium of the paintings.
Let’s understand the medium of paintings that we have collected. Saying I have collected paintings is too abstract right. Time to go deep!
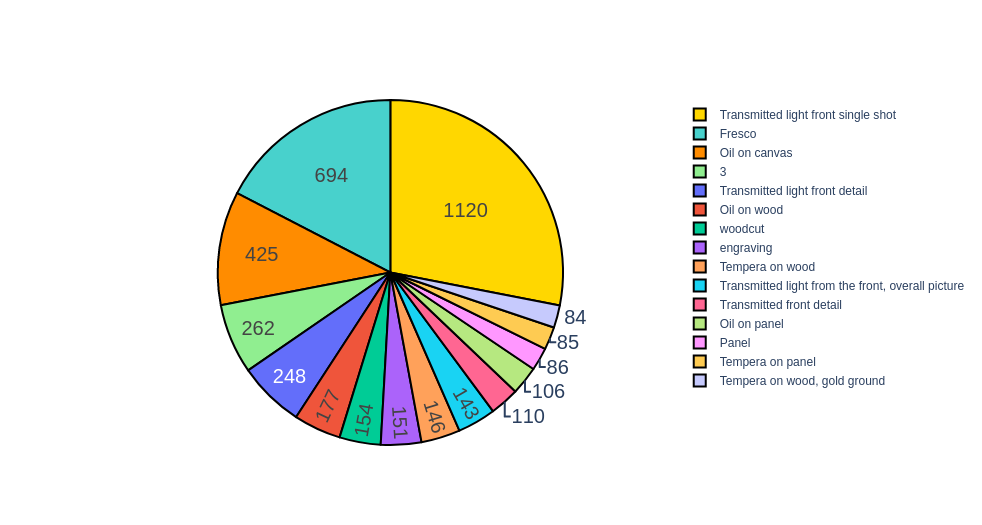
So what we observe are more variations like tempera, oil on wood, oil on canvas and transmitted light front single shot. These are weird names to me but nonetheless we get the idea as to what I have collected.
Analyzing the descriptions, captions
It is a bit difficult to qualitatively analyze each caption and hence I have just analyzed the lengths of the textual data.
Titles
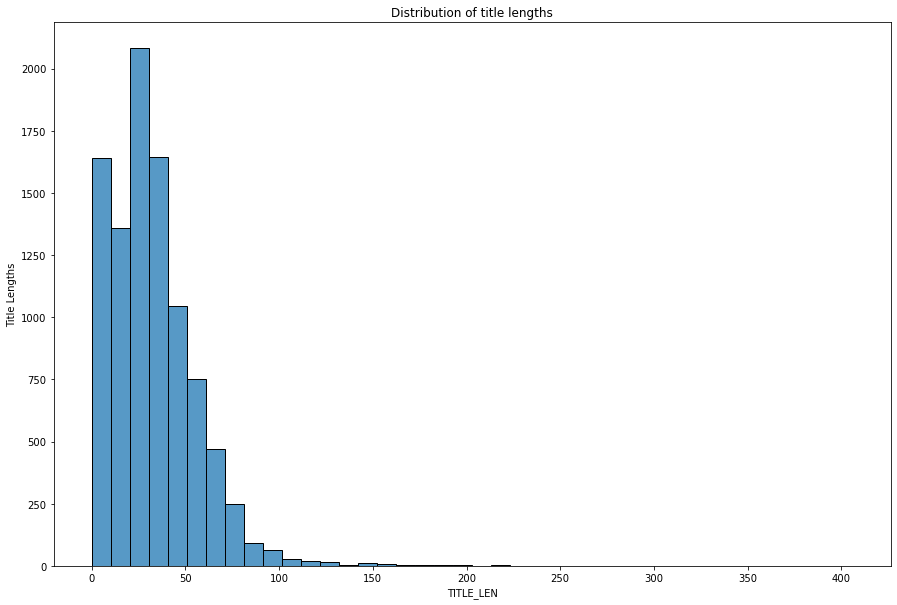 From this I can say that the titles are relatively long even for a title. While I was scraping this data what I observed was that some titles were good enough to be used as captions as they were able to correctly describe the painting in short words.
From this I can say that the titles are relatively long even for a title. While I was scraping this data what I observed was that some titles were good enough to be used as captions as they were able to correctly describe the painting in short words.
Descriptions
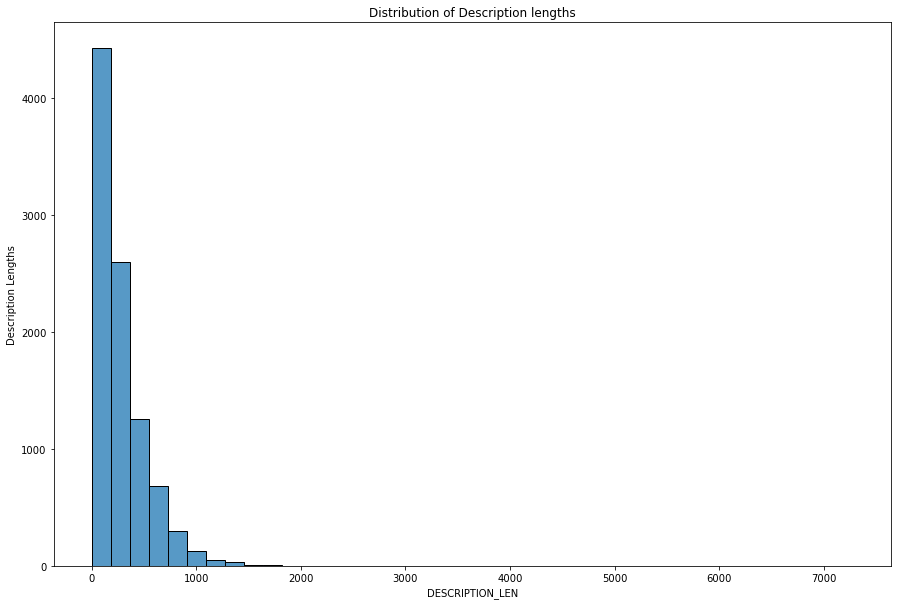 In order to build a good captioning model we need captions that describe paintings on a contextual level and hence I have scraped images only from museums as they normally contain descriptions that are tagged by people that have certain level of expertise in this. They don’t just describe the painting they also have the ability to describe the style and strokes of the artist.
In order to build a good captioning model we need captions that describe paintings on a contextual level and hence I have scraped images only from museums as they normally contain descriptions that are tagged by people that have certain level of expertise in this. They don’t just describe the painting they also have the ability to describe the style and strokes of the artist.
Collections
The last thing I analyzed from the metadata was the places that it was collected or the artists who made it.
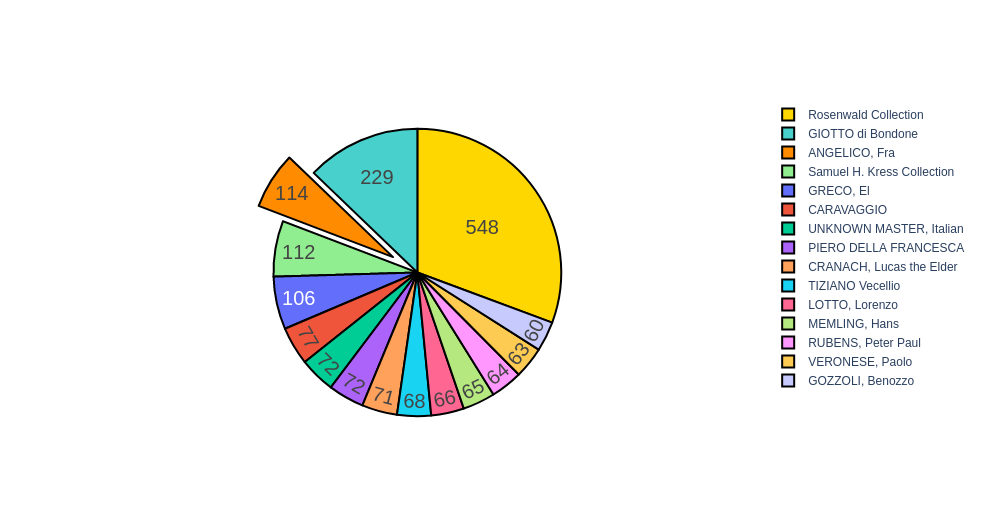
Image-Captioning Process.
After curating the images, the next step in the Emile Male Pipeline is to tag them. I had started with this in the last week after having a meeting with my mentors. Currently, I have only completed the object-detection part in the pipeline.
Object-Detection Module
One of the first steps in the pipeline is to extract objects(saints, their attributes etc) and then pass them up to the encoder of the transformer. The only problem was that there was no dataset with bounding boxes present to identify saints, Mary, Jesus etc. So the first task was again to curate. For this I used the images that I had from the curation process and annotated 200 of them with various classes down below.
- Angel
- Baby
- Book
- Christ
- Cross
- Crown
- Flower
- Fort
- Fruit
- Mary
- Saint
- Sheep
- Staff
Samples
 Following are some of the samples I recorded while creating bounding boxes. I have tried to annotate as much details I could understand based on the captions I had captured. Initially the dataset I had collected 53 labels as a result of which the model was performing poorly. I think that is because we would need more instance of each objects if we annotate the image to a higher extent. Hence I reduced the no of labels to 13 and the model performed considerably better even with 200 images.
Following are some of the samples I recorded while creating bounding boxes. I have tried to annotate as much details I could understand based on the captions I had captured. Initially the dataset I had collected 53 labels as a result of which the model was performing poorly. I think that is because we would need more instance of each objects if we annotate the image to a higher extent. Hence I reduced the no of labels to 13 and the model performed considerably better even with 200 images.
Note: I performed further augmentation (i.e horizontally flipping some images) to increase this size to 300. The final dataset is available for download here. The samples are in the YOLOv6 format.
The detection
After building the dataset the next step is to work on the model that can extract bounding-boxes i.e the iconographic content from the images. For this I decided to use YOLOv6. I had used other models like F-RCNN but I didn’t get good results with it.
YOLOv6 Architecture.
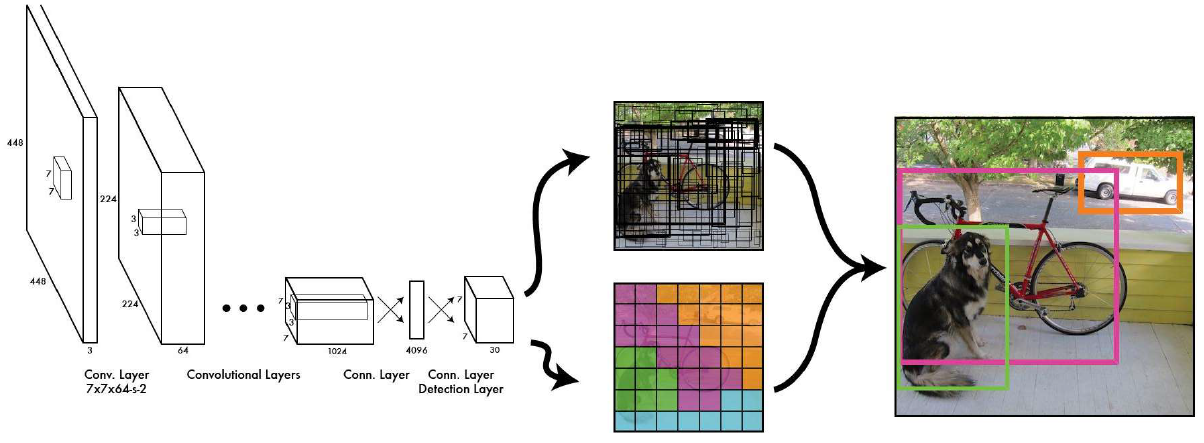
Working of YOLO
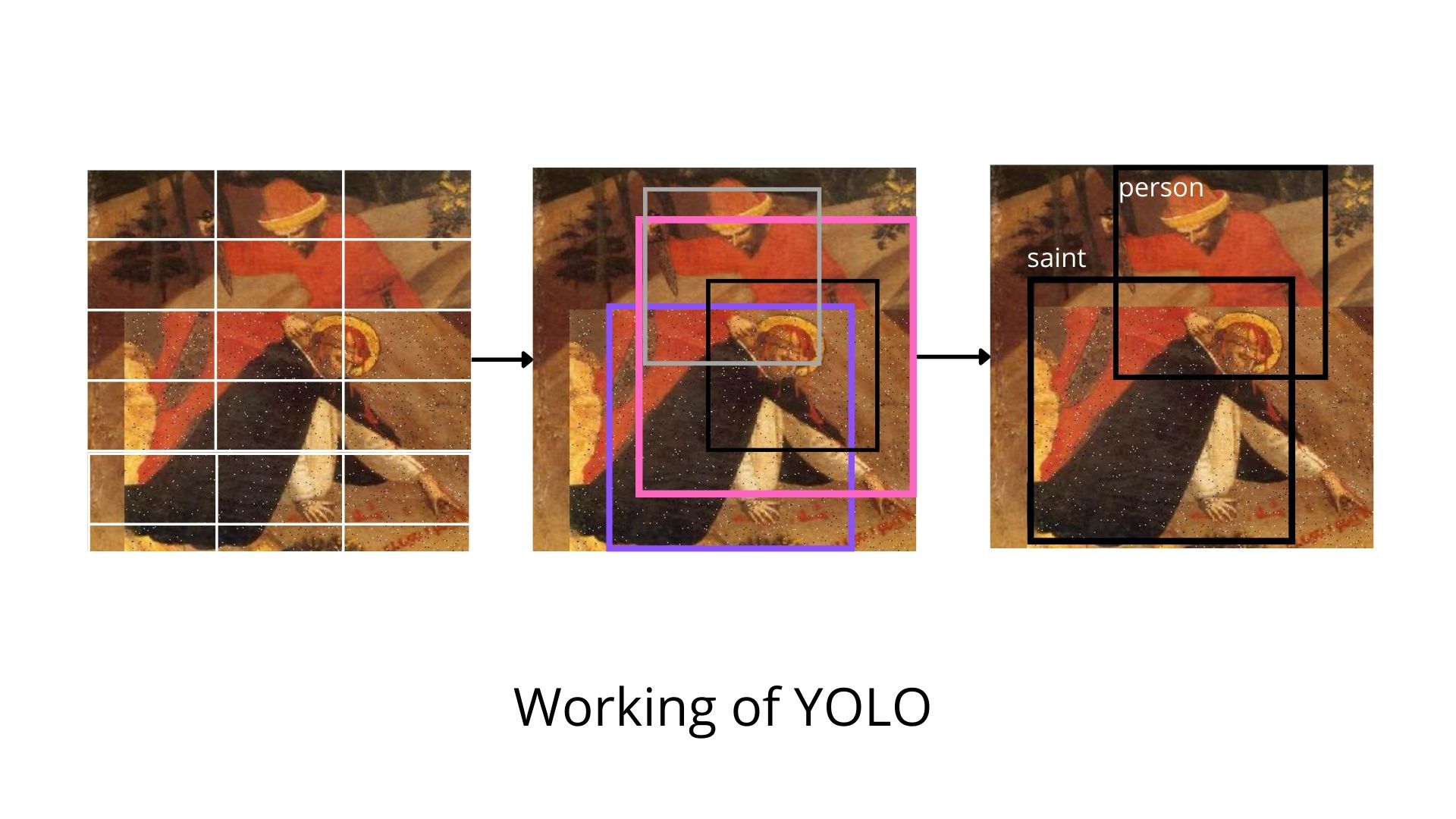 The working of YOLO is simple. What it does is that it divides an image into N grids where each cell has a size S*S. Each of these N grids is responsible for the detection and localization of the object it contains.
The working of YOLO is simple. What it does is that it divides an image into N grids where each cell has a size S*S. Each of these N grids is responsible for the detection and localization of the object it contains.
The cells present in the grid are used to generate the B bounding boxes. These bounding boxes contain the label predicted and the probablity of object being present in the bounding box. Also the bounding box that is generated is relative to the location of the cell.
The advantage of this procedure mentioned is that the detection and classification happens in a single step unlike F-RCNN where we have to first extract features then extract boxes from FPN.
Results with YOLO
Example-1
 So after training the model for 400 epochs. We put the model to test. The above images are some good example that showcases the working of the model. We are able to distinguish various sections in the painting with ease. If we take for example the second image. It is of a young John the Baptist and I am sort of impressed that it is able to see that along with other attributes like a book and a cross. That means our model is learning something and is not just making naive guesses.
So after training the model for 400 epochs. We put the model to test. The above images are some good example that showcases the working of the model. We are able to distinguish various sections in the painting with ease. If we take for example the second image. It is of a young John the Baptist and I am sort of impressed that it is able to see that along with other attributes like a book and a cross. That means our model is learning something and is not just making naive guesses.
Example-2
 Following are the results where the model fails miserably. The second image for instance predicts the person in painting to be that of Mary but we know it is not that. In face if we observe the person detected is actually executing someone. This is probably because while annotating a lot of the images consisted of Mary in them and so maybe the model has some bias towards it. Another image I will consider is the fourth one where there is indeed Christ in the painting but the model is not getting the bounding box right. This might be because most paintings show Christ hanging on a cross so maybe it could explain why Christ is detected close to a cross.
Following are the results where the model fails miserably. The second image for instance predicts the person in painting to be that of Mary but we know it is not that. In face if we observe the person detected is actually executing someone. This is probably because while annotating a lot of the images consisted of Mary in them and so maybe the model has some bias towards it. Another image I will consider is the fourth one where there is indeed Christ in the painting but the model is not getting the bounding box right. This might be because most paintings show Christ hanging on a cross so maybe it could explain why Christ is detected close to a cross.
How to improve?
I think the main thing is that we need more data so for that we will have to annotate more instances and also more variations in the art styles as there is no guarantee that everything would work if there was a stained glass painting. Next we also have to annotate more objects in the paintings. For instance if we observe the last painting in Example-2 we see there is also a lion in the painting which is usually seen in some St Jerome paintings. So those attributes will further help in building a rich image-captioning model.
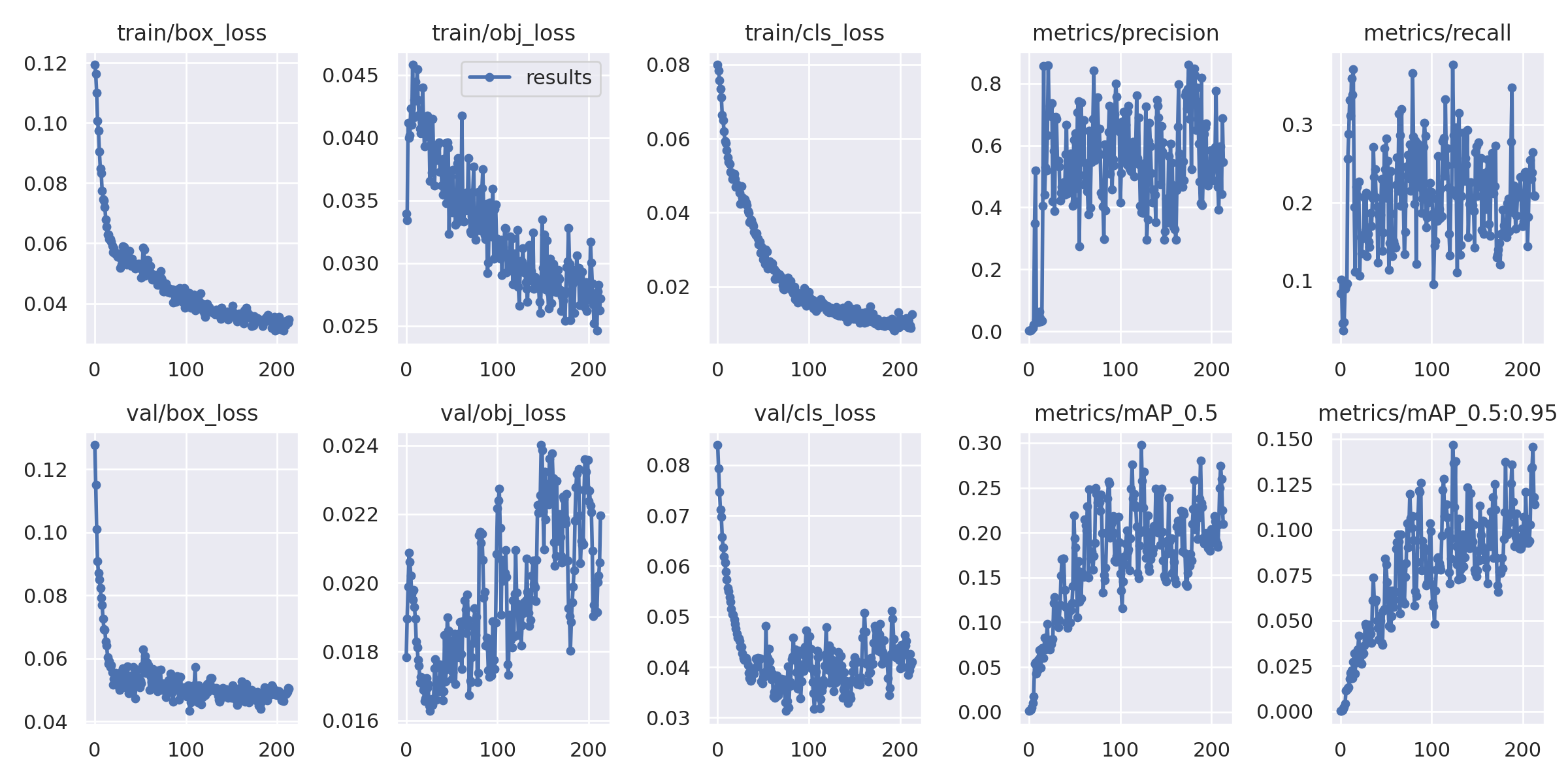
Quantitative Result with YOLO Training.
Splits
- Training = 241 Images
- Validation = 38 Images
- Test = 20 Images
Results on test set
- mAP over all the classes - 29.8%
- Precision - 38.5%
- Recall - 37.7%
Training Graphs
What’s next?
While the model is not perfect, I still can give an overview of what comes next.
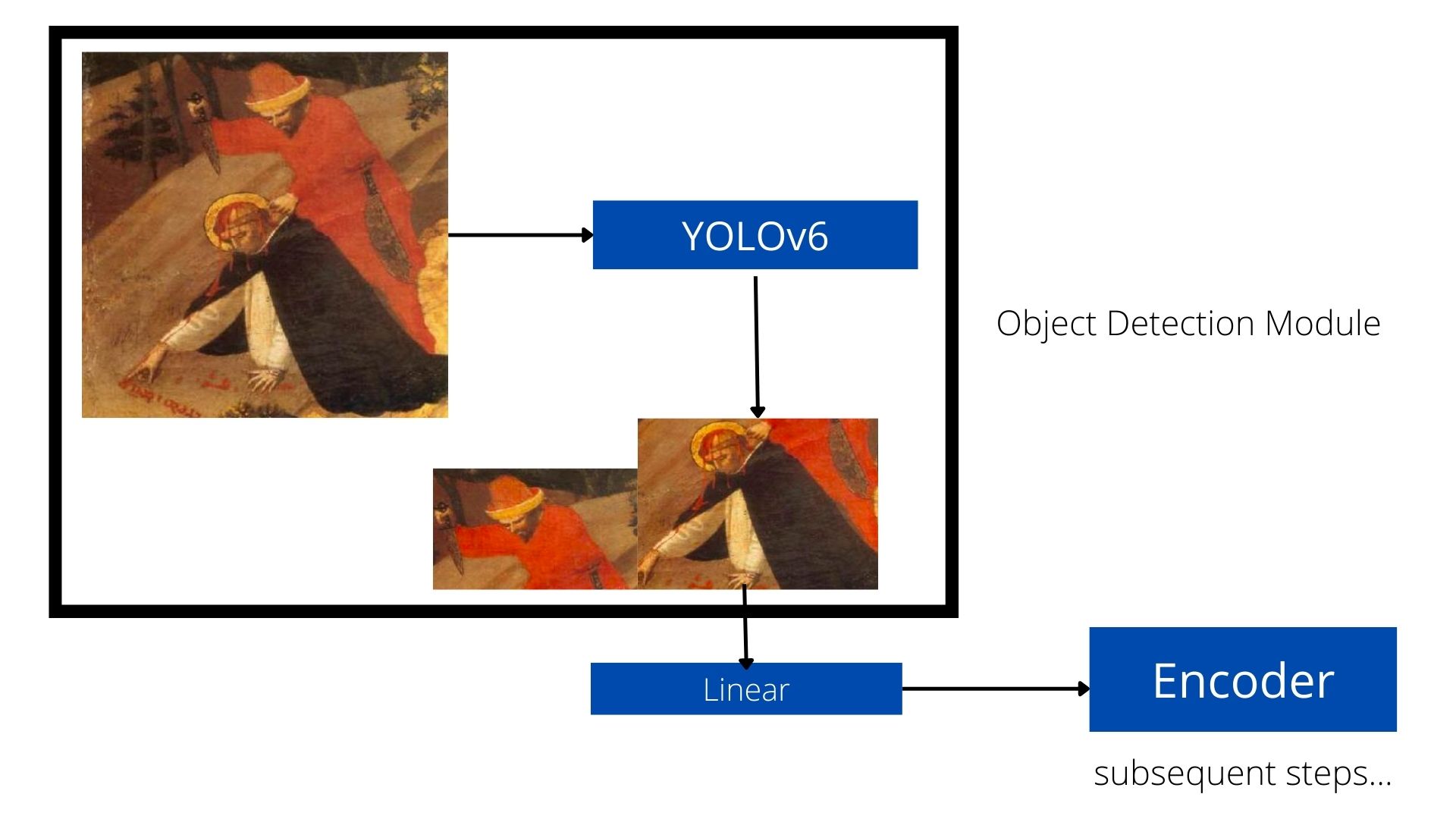
So the idea is to use the created object-detection module to extract features. The features extracted will be then fed into a linear layer which will give us a fixed-length representation. Next this will be passed into the encoder block which will give us some other representation to be used in the process for generating the captions.
Timeline for the next phase.
The next phase will be focussed upon building the bigger module for the Emile Male pipeline i.e to caption paintings. Now that I have collected good amount of images. My next step is to work on the model proposed and the deployment of the pipeline.
What can i do better in the next phase.
- The first thing is to improve the object-detection module such that it can extract more attributes.
- I think thinking from the respect from what are my inputs/outputs is important as I got heavily involved in curation because of which I didn’t have enough to show during the first phase
- Keeping it simple I think.